As I talked about in CSS Binary Format, it seems that the CSS properties are quite redundant for most of the web; It would be great if we could somehow encode that data, w/o needing to list those string values in the compressed stream itself.

You see, when creating dictionary compression algorithms, you typically need to send the dictionary along with the byte stream where each element of the stream contains a reference to an element in the dictionary. For some cases where the dictionary data is large enough to be encumbering, then large wins can come from figuring out how to remove the dictionary words directly from the stream, and somehow move it into the codec.
As it turns out, there’s a subset of CSS text-definitions that exists in the browser, that you can recover @ runtime, which could allow us to remove that data from the compressed file.
This means that we do not need to include those source strings in the file, rather we encode our file expecting that the indices to the property names point to the table we generate from the browser data.
Getting the property names on the client
Luckily for us, calling document.body.style from Javascript will give you a dump of all the CSS properties that the browser supports, and after a little data-modification, can be reconstructed. (the data given back to you is not format-exact with CSS standards for some reason...)
for(var i in document.body.style) {
for p in props:
string = ""
for l in p:
if l.isupper():
string += "-" + l.lower()
else:
string += l
}
|
To get this working, I replace the property name in the file with a string-ized index into the array provided from document.body.style. This is easy to identify in the file, as most of them come immediately after a semicolon. How you save this information to disk is up to you, and your workflow.
Encoding the file, offline
This process is pretty straight forward. Once we have the property names for Chrome, (or whatever browser) we can parse the input CSS file, and simply replace any CSS property names in the file with a numeric lookup, coupled with some token value to allow us to find this information later.
for i in range(len(propTables[1])):
symb = propTables[1][i]
dat = dat.replace(symb,"^" + str(i))
|
Results
src(bytes)
|
src.zip
|
pne
|
pne.zip
| |
1k.css
|
157
|
107
|
127
|
97
|
4k.css
|
3,330
|
1,068
|
2,929
|
1,005
|
15k.css
|
14,905
|
3,016
|
12,912
|
2,900
|
96k.css
|
97,452
|
15,537
|
85,087
|
15,046
|
219k.css
|
223,865
|
42,769
|
189,360
|
41,562
|
You can see that this method easily saves us +10% for basic compression. What's nice is that we seem to keep an additional 2%-4% of GZIP compression post-transform; Which means this is a great technique to add to your stack. Or rather, this is the first technique I’ve presented which acts as a text compression booster. I hypothesize this is due to the property names in a CSS file contributing in the minority of entropy in the file, and so removing it minimizes the file without accurately modifying the entropy. More on that later though..

Recovering on the client side
Firstly, i want to be clear that this particular technique requires you to reconstruct the CSS file, post GZIP decompression, before handing it off to the DOM. For many developers, this doesn’t make sense, simply because their site loads fast enough, however for web-app developers, who may already have a site which needs heavy CSS fixes, this may be a viable path.
The decompress stage of this algorithm that occurs on the client side will have to do string-replacement / concatenations; this can be fast, or slow depending on your implementation.
Our goal is to effectively replace any “^#” tokens with the original value. To do this quickly, we :
- tokenize the string via the “^” character
- For each token, read until you hit the “:” character
- parseInt(substring) is the index into the client CSS list.
- outstring += doc.styles[idx] += token[colonSpot:len]
I was shocked at how fast this was, turns out that most of the web browsers are optimized for string concatenation over string-joining nowadays. You can see the results in various jsPerf tests or here, or here again.
Browser string optimizations have changed the string concatenation picture.
Firefox was the first browser to optimize string concatenation. Beginning with version 1.0, the array technique is actually slower than using the plus operator in all cases. Other browsers have also optimized string concatenation, so Safari, Opera, Chrome, and Internet Explorer 8 also show better performance using the plus operator. Internet Explorer prior to version 8 didn’t have such an optimization, and so the array technique is always faster than the plus operator.
|
Of course there’s a whole separate discussion about the fastest way to get it into the dom, which I recommend using document.fragment based on these tests
This works... kinda...
THE LARGEST DOWNSIDE to this technique, however, is that each browser's document.body.style is different. Meaning this ties our dictionary creation to a particular rev/browser depending on how variant the result of that line of code is.
To use this technique, you need to issue different files for different browser-listing of css support. And then, as updates came out, you’d need to push a new build of the CSS to the servers.
This single issue generally kills this technique for most web-devs; there’s just too much gardening involved.
How often do the property lists changes?
For the sake of argument, let’s figure out how often CSS properties have changed in a measurable way for web browsers. Thankfully Chrome keeps a running list of it’s historic builds, and considering that they run on 6 week cycles, we have the ability to test, and chart how often CSS values have changed in the past 2 years.
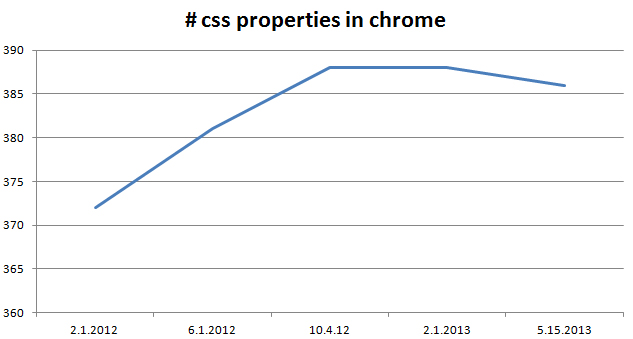
I was able to chart builds of Chart builds of chrome for every 3 months over the last year, You can see the large spike over 2012 as the CSS3 features started to land in Chrome. Oddly we’ve seen a taper-off over the last few months, which I find interesting in itself; Perhaps this has to do with blink? or maybe my way of measuring CSS values is flawed with the module-based setup of CSS4?
Is this worth it for you?
I’m not really sure?
It might be worth considering the fact that you also have to reconstruct the css before passing it off to the DOM for evaluation and propagation, which could be a deal-breaker for most CSS files that are on the fast-path for ‘pixel to screen’ time. However for web-apps, this may be a win; especially considering some web-apps have 250k css files that they send down to the client.
It’s interesting to note that removing the property names for lots of files still leaves entropy in such a state that we can gain compression from GZIP on it;
Perhaps this fits the bill better for your mobile-specific sites? These tend to have less variance between browsers (so fewer unique CSS files to use), and usually a separate content layout, which makes more sense to attach to.
Although we are fighting an issue here, in that we can send down a smaller file to mobile, but then caching becomes an issue. That is, every time the web app boots, we need to decompress the file again from cache, which is less than ideal.
You can find the source code to this experiment on my github account.
You can find Colt McAnlis here:



Nice post!
ReplyDeleteThe reduction in the number of properties may be caused by chrome removing '-webkit' prefixes in properties as they make it to the core of supported properties.
That's a little too deep for me. It's good to know.
ReplyDeletesecure airport parking Heathrow
Heathrow parking deals
There is so much to learn about this stuff.
ReplyDeleteorlando magic tickets online
buy orlando magic tickets
Thank for your very good article.! i always enjoy & read the post you are sharing!
ReplyDeletethai porn
Thanks for sharing these very helpful details.
ReplyDeleteManchester park and ride
cheap park and ride Manchester