The overly verbose nature of formats like JSON and XML have given rise to binary versions of their data in order to save transfer size, and are used by many large companies due to their savings. Although playing “Follow the leader” isn’t my style, I decided to try my hand at a binary version of CSS would be similarly successful.

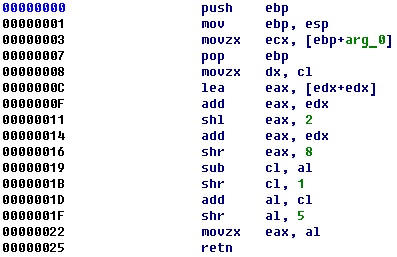
If you simply look at the structure of a CSS file, it looks a great deal like structured assembly code, where each line defines an operation, and parameters to that operation.
{kind=link}
With this in mind, it becomes naively straightforward to view a CSS file as a series of assembly operations
Simplistically:
h1 {
color:black;
margin:15px 8px 90px;
}
|
Can be re-represented as a set of ASM-ish instructions, alongside a variable table:
“h1”,”black”,”15px”, …..
|
That is, we redefine a CSS Name:Value pair to look like an assembly instruction with multiple inputs. Since the inputs are raw text, we keep a dictionary of them, such that the input to our assembly-style instructions is simply a pointer into the variable table.
There are a few benefits of this format:
- We represent input data as a dictionary, so multiple uses of the information are saved.
- The dictionary-keys section of the file should compress well with a dictionary + statistical encoder
- Common human-readable items, like spaces, semicolons and brackets are removed from the format by factor of its’ layout, which will reduce size more.
Tokenization

Tokenizing is mostly the easy part of this process. For my simple tests, I used the python tinycss module, which handled all the heavy lifting of parsing the data and assigning type context for me. The tokenization is simplistic, once tinyCSS parses the data, I crawl through, property-by-property and output an Assembly-style string.
A nice thing about the tinycss module is that it allows me to get property type information, so I can tell the difference between a value, number, and a string. During parsing, I push these values into type-specific tables (e.g. all the strings go in one vtable, all the ints in another), because this reduces the overall size of indexes that I have to use and reference in the file.
As noted, the entire point of the vtable is to remove redundancy from the file; if the value “10px” is already in the table, we can encode a pointer to it, multiple places in the stream
Dealing with lots of indexes
Ideally, each line in the file is a single list of byte values, where inputs point into the dictionary table. For larger files though, our variable table can easily exceed 255 items, so we can’t simplistically push a byte-per-index to our file, and it would be less than ideal to push the max value per index, instead it would be great to only write out the bits that we need.
 This problem is not a new one for compression, although we’d love to just write bytes where the index is less than 255, and shorts where the index is less than 65536, we run into the problem of how to tell the two apart in our byte stream effectively. Most compression systems approach this through means of Universal Codes, which have been around for quite some time. These are variable-length bit-codes that contain uniqueness and length information as properties of the code. Because of these two features, they are easily parsible, and can be recovered properly (as opposed to a raw stream of binary data). They also tend to be simpler and faster to decode than their cousin, Huffman codes. These features come with a cost however, in that Universal codes tend to be bloated compared to their direct binary counterparts. For my purposes, I used a Fib3 universal code, which when compared to other codes, provides a good compromise between robustness and length. (Note, there are variable byte codes: Tagged Huffman, and Dense Codes, however I will cover those and their effectiveness in a later article)
This problem is not a new one for compression, although we’d love to just write bytes where the index is less than 255, and shorts where the index is less than 65536, we run into the problem of how to tell the two apart in our byte stream effectively. Most compression systems approach this through means of Universal Codes, which have been around for quite some time. These are variable-length bit-codes that contain uniqueness and length information as properties of the code. Because of these two features, they are easily parsible, and can be recovered properly (as opposed to a raw stream of binary data). They also tend to be simpler and faster to decode than their cousin, Huffman codes. These features come with a cost however, in that Universal codes tend to be bloated compared to their direct binary counterparts. For my purposes, I used a Fib3 universal code, which when compared to other codes, provides a good compromise between robustness and length. (Note, there are variable byte codes: Tagged Huffman, and Dense Codes, however I will cover those and their effectiveness in a later article){kind=link}
To use these codes, we tokenize our input CSS data, and count the max number of variables, we then generate a table of Fib3 codes to cover that.
Note, we separate out each type into their own bucket so that indexes remain small across types. This adds about 16bits of overhead per bucket we use, simply because we need to keep track of it.
The format:
Here’s the proposed format, in all it’s raw form:
Header data
| |
1 byte
|
Control data (numeric control, etc etc)
|
16 bits
|
num Declaration strings
|
16 bits
|
num Property strings
|
16 bits
|
num value strings
|
16 bits
|
num value numbers
|
Variable Tables
| |
XX bits
|
declaration string table (strings written as [len(short)][chars(byte)])
|
XX bits
|
property string table
|
XX bits
|
value strings table
|
XX bits
|
value numbers table
(values written based upon the numeric control above)
|
Symbol Stream
| |
0xFFFF 0xXX
|
fcn will always be 0xFFFF, followed by a 8 bit pointer to the decl table
|
0xXXXX 0xYY
|
property single input -
16 bits pointing to the static property table,
8 bits pointing to the variable table, variables are all offset
|
0xXXXX 0xYY [0xZZ ..]
|
property multi input
16 bits pointing to the static property table,
8 bits for number of inputs
Array of bytes pointing to variable table
|
Results:
I encoded some CSS files of various sizes to see what savings we get, and then GZIP’d the data after encoding, to see how that fares. Smallest results are in bold.
src
|
src.gz
|
binary
|
binary.gz
| |
1k.css
|
157
|
109
|
98
|
126
|
4k.css
|
3,330
|
1,073
|
2,349
|
1,430
|
15k.css
|
14,905
|
3,016
|
9,258
|
4,375
|
96k.css
|
97,452
|
15,537
|
59,877
|
20,599
|
219k.css
|
223,865
|
42,769
|
113,465
|
55,873
|
So you can see that the Binary CSS format easily cuts the size of the file by 30%+, but sadly, fails to produce a post-gzipp’d file that’s smaller than just gzipping the source file. Once again, we’re running into the GZIP threshold.
The GZIP threshold.
The point in which a modified version of the file fails to produce a smaller post-compressed result, when compared to a compressed version of the source file.
Or rather, once GZIP(MODIFIED(FILE)) > GZIP(FILE) then You’ve gone too far.
|
This made me question those other binary formats, after all, shouldn’t you be GZIP’ing those as well? After some searching, I found no mentions of how MSGPACK stands up to gzip compression; I’m guessing they are in the same boat; the binarization process proves to remove too much information, and GZIP falls over. Although I suppose the MSGPACK folks fall into a particular use-case here, namely that in some cases, constructing the static binary JSON data is faster than gzipping things, so you can construct a light version, send it to the client ASAP. Sadly, CSS doesn’t appear to fall into that category.
NOTE : TinyCSS module ignores some very important things, like @media etc. I’ve carefully selected files such that this would not play a factor into the calculation

An extension, could we remove the variable table?
Although variable tables are quite common, I wanted to take a swing at seeing if we could simply enumerate all the potential property names and values by frequency, and add this data to the codec, rather than the encoded data stream.
To determine if this was feasible, I cached the HAR files from the top 1000 sites listed in HTTPArchive, and then downloaded all the referenced CSS files, and created a large histogram across all the CSS for property names and used values. (Note, this is almost identical to my previous post on calculating website costs with HAR files, which has source code)
Here's what I found:
The top 10 properties
Here’s the top 10 used properties, the number of times they were used, and the estimated total number of bytes that character string occupies across our corpus.
Name
|
# appearances
|
total # bytes
|
width
|
234,872
|
1,174,360
|
background
|
169,695
|
1,696,950
|
height
|
161,969
|
971,814
|
color
|
159,828
|
799,140
|
padding
|
146,744
|
1,027,208
|
background-position
|
133,610
|
2,538,590
|
display
|
131,790
|
922,530
|
margin
|
124,105
|
744,630
|
font-size
|
121,260
|
1,091,340
|
float
|
105,938
|
529,690
|
The top 5 values for the top 10 properties
For the top properties, I felt it was interesting to highlight the top values used for those properties, and how often they are used across our corpus.
Property
|
value 1
|
value 2
|
value 3
|
value 4
|
value 5
|
width
|
100%:20896
|
auto:7485
|
16px:4079
|
300px:3841
|
20px:3084
|
background
|
no-repeat:
66284
|
0:40576
|
transparent:17279
|
left:12322
|
#fff:10449
|
height
|
20px:7318
|
100%:6236
|
auto:6018
|
16px:5576
|
30px:5067
|
color
|
#fff:18420
|
#000:10273
|
#333:9303
|
#666:8515
|
#999:5906
|
padding
|
0:127117
|
10px:31633
|
5px:27347
|
2px:12600
|
4px:12117
|
background-position
|
0:60397
|
0px:7494
|
left:6142
|
right:4346
|
-32px:3717
|
display
|
block:64186
|
none:26438
|
inline-block:22158
|
inline:14182
|
table:1899
|
margin
|
0:162625
|
10px:19991
|
auto:15200
|
5px:14898
|
0px:12922
|
font-size
|
12px:19524
|
11px:16837
|
14px:11748
|
13px:7724
|
10px:5663
|
float
|
left:75766
|
right:24194
|
none:5903
|
center:29
|
inherit:15
|
What is truly amazing about this table, is that somewhere in the universe, a thousand web developers have decided that padding:10px is a better padding amount than 4px. Or that float:left is used almost twice as much as float:right.
The top 20 property values
If we transpose the data, and just look at the most used property values, independent of the property itself, we find another interesting table:
absolute:23268
|
pointer:11257
|
transparent:10507
|
sans-serif:10489
|
left:9498
|
Arial:7055
|
block:6203
|
Helvetica:5552
|
right:5319
|
0:4702
|
bold:4671
|
solid:4547
|
1px:4324
|
no-repeat:4279
|
2px:4145
|
relative:4084
|
17px:3729
|
normal:3522
|
auto:3415
|
repeat-x:3402
|
What this means
Firstly, from my direct interest of determining if there’s a way to create a static dictionary for the top 16k values, this test has shown that to be less than an option, unless we implemented it directly into the browser. Looking at just the unique values, the top 1k sites lists over 151,383 unique values, which would require 32 bits to represent in lookup table, and would need to include the unique values somewhere in the file to represent.
If we were attempting to simply make a javascript library which contains this type of static dictionary, then we’re going to lose more in the existence of the data in JS, than what we would save by removing it from the CSS files.
And really, this is a skewed result for developers, directly. HTTPArchive lists that the average website in their test suite contains about 15 JavaScript files an 5 css files, meaning that even if we did enumerate each property name for CSS, we wouldn’t get much savings for this single developer; I mean IF you just count the characters, the top 10 property names, across 1000 websites only account for ~11mb of traffic
Effectively, this means that we need to put our variable data in the file, and point to it from each line in our binary format.
The code
You can find the encoder for this experiment on my github account. Since the testing showed negative gains, I did not spend the time to write the decoder; I offer the code warranty-free as a proof of concept for anyone out there who’s got better ideas.
You can find Colt McAnlis here:



The point of binary CSS shouldn't be to gain bandwidth but to stop parsing text like mad men: parsing binary files is much more secure and faster.
ReplyDeleteThanks for sharing this.
ReplyDeleteREDUCE BOUNCE RATE
PLEASE stop changing the page when I zoom in on mobile. Jesus Christ it's annoying.
ReplyDelete